半角の「¥」記号がついた金額表示は日本ではよく見かけます。
更に日本では金額の3桁毎に「,」(カンマ)を挿入する習慣があります。
こんな風に。
¥1,280
Pythonを使って、こうしたデータから数値のみ取り出す方法です。
やろうとしている事
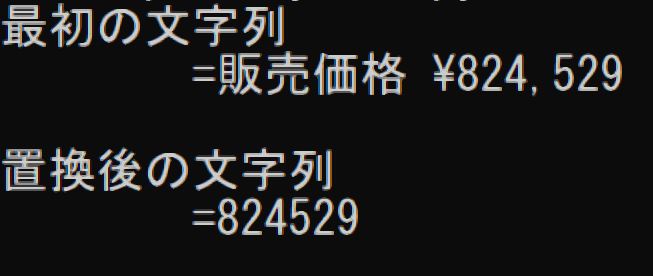
こういう文字列を
販売価格 ¥824,529
こうしたい。
824529
ソースコード
正規表現を使って、「¥」と「,」と数字以外の文字を消去する、という事で数値のみを取り出してみます。
deleteYenCamma.py
# -*- coding: utf-8 -*-
"""
半角¥マークつきの金額部分の数値のみ取り出す
例)販売価格 \824,529 --> 824529
"""
import re
# 元の文字列
before = r"販売価格 \824,529"
print("最初の文字列\n\t={0}".format(before) )
# 「\」と「,」と数字以外の文字を消去する
after = re.sub(r"\\|,|\D", "", before)
# 取り出し後
print("\n置換後の文字列\n\t={0}".format(after))
解説
Pythonで正規表現を使うには、import reを宣言します。
reモジュールには、subという正規表現を使って、文字列置換できるメソッドが存在します。
re.sub(検索文字列, 置換文字列, 対象文字列)
subの第1引数は正規表現で記述するため、
r”\\|,|\D”
は正規表現となっています。
最初の「\\」で半角¥を表します。「\」を2つ続けて記述しているのは「\」という文字がエスケープ文字のためです。1つにしてしまうと文字列が括られていない扱いになり実行エラーとなります。
「,」は半角カンマを表し、「\D」は数値以外の文字を表しています。
途中の「|」|記号は、「または」という意味です。よって、「¥」または「,」または数字以外の文字を検索しなさい、という意味になっています。
続いて第2引数
「“”」は、置き換え文字として文字列なしを選択したことになります。よって第1引数の意味とあわせて「¥」と「,」と数字以外の文字を消す、という意味になっています。
変数beforeが、置き換え前の文字列、変数afterが数値のみが入った文字列になります。
ただし、この時点では変数afterの値は、文字型です。もし取り出した数値で計算をしたい場合は、re.sub実行後に
after = int(after)
とすれば整数型に変換できます。(計算可能な数値になるということ)
以上、Pythonで半角¥マークつきの金額部分の数値のみ取り出す、でした。
コメント